High Availability
What is it? What does it do for my business?
We are all familiar with the term “High Availability”.
Most InfinityIT sites implement HA Firewall solution to mitigate against a Firewall failure. Why?
Because Internet and inter-site connectivity is very important, and we all want to minimise the possibility of downtime – right?
But what happens if your server fails? What safeguards have you in place to ensure an effective business continuity plan?
Remember that server fault which we spent 1 hour troubleshooting?
Well, now it requires a replacement part which will take at least 4-5 hours to arrive and could take the engineer another 1 – 2 hours to fit it.
If you are lucky the part will fix the issue and you’ll be able to open as normal tomorrow. But what about your “business image”, what about the inconvenience to your customers?
Your data is probably the most important asset you own, without it you cannot function. That is why we take backups locally to NAS, and offsite to Cloud. It’s the reason we have AntiVirus, Firewalls, and Servers, It's why we do Pen Tests and DR Tests, It's why you hire people like us, It is all done to ensure your data is safe, secure, and readily accessible, but only to those that should have access to it!
A huge portion of your business data is held on your servers, So if your only server fails then you are effectively shut down until your IT people can get you up and running.
High Availability Servers
At any point in time, your Data exists on both servers. Your VM's can be moved to the 2nd host in seconds with no downtime. If 1 server fails, VM's can be booted up on another host with little or no downtime and more importantly, no data loss.
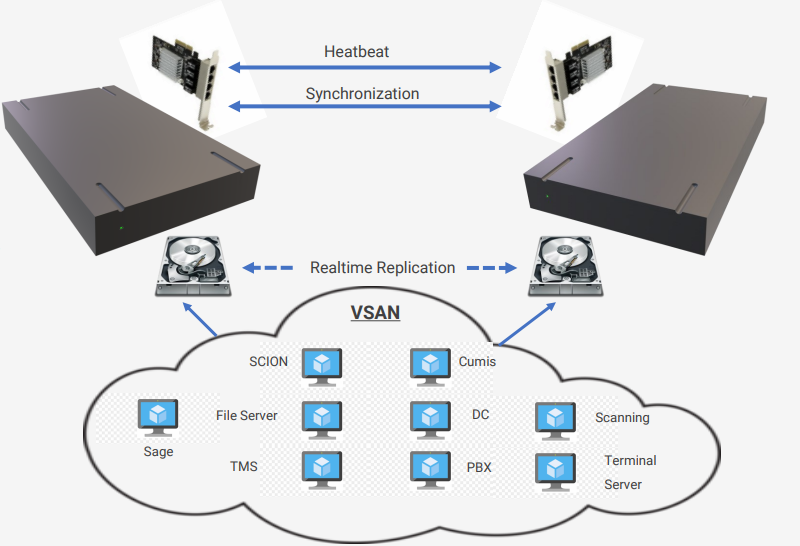
Imagine the following scenario

Single Server failure
Typical downtime – up to one day
All Systems are down resulting in you having to close your doors.
Cons:
Possibility of 4-5hrs before replacement part can be onsite, Depending on the nature of the fault there may be data loss, and backup restores may be required further adding to downtime. If a single server goes down due to hardware failure, your business will most likely be closed for a full day.
Point in time replication (Veeam)

Typical downtime 2-4 hours
Replications are taken at regular intervals, i.e VM’s on server 1 are copied to server 2. At all times you have VM’s ready to boot up.
Pros:
You have a working system “ready to go” on the 2nd host, albeit the data can be up to 1 hr old
Cons:
1. Data on the 2 servers will be inconsistent, it can take considerable time and effort to bring Server 2 up to date before going live.
2. You potentially have 1 idle server (at least until 1 fails)
3. Hypervisor and Firmware updates will require downtime
Server Cluster / vSAN
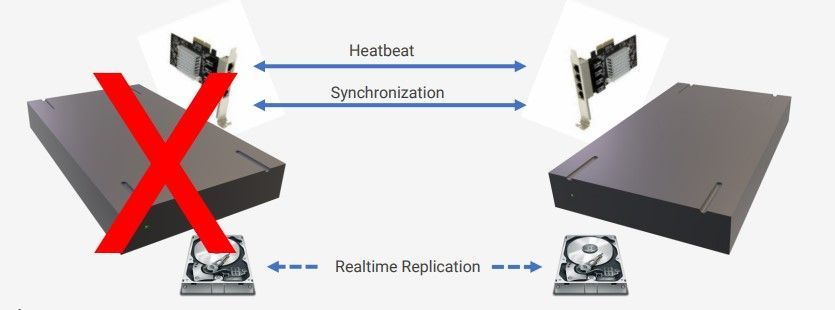
Typical downtime 3 – 4 mins,
If host 1 fails all the VM’s on it will begin booting up on host 2 automatically.
Pros:
1. No data loss,
2. Server 1 can be repaired and brought back into production with no further downtime.
3. Server 2 can be fully utilized as a second server and VM’s moved between both hosts as required
4. Patching and firmware updates can be done to hypervisors and hardware with no downtime of services
Cons:
Storage requirement are doubled, both hosts need to have enough storage for all the VM’s on each host
What sets our solution above others
1. Some HA solutions require a 3rd node, adding to the cost of hardware, Ours requires only 2.
2. We don’t require specially certified hardware If your hardware can run VMWare, Microsoft, Oracle or Redhat Hypervisors, we can use our solution to give you HA. We can even run it on an Azure stack.
3. We can usually provide HA at a fraction of the cost of the proprietary vendor such as VMWare
4. Our Solution is backed by a 24/7 NOC, we don’t just monitor outages, we monitor and get alerts on things like storage latency and re-sync issues on the cluster.
5. As a testament to the robust and cost-effective nature of the solution We have implemented it across over one third of our financial customers in the last 2.5 years.
Questions and Answers
Q. We have Disaster Recovery in the Cloud, We test it every year and never have an issue during testing, Why do I need a solution like this?
A. DR tests are generally done in a very controlled manner, In reality, they rarely replicate the “unknown” of a real disaster. For example, Cloud backups are not real time. After we boot up the VMs in the cloud, You still need to figure out what data you have versus what data you need before you can open the doors, There will be data to be re-entered, this might involve the help of 3rd parties. DR is not intended to be a quick fix to any business outage, there are a huge number of things to consider before, during, and after you decide to move your production to the cloud in a DR situation. In fact, your DR solution should only be considered as a last resort option. Remember once your server is fixed everything now working in the cloud needs to be copied back to your server, this means further downtime.
Q. Aren't hardware failures very rare?
A. Yes, but that doesn’t mean they won't happen..
In the past few years, there has been a huge focus on security which often means applying patches and firmware updates that may not have been done on a
regular basis before. Applying updates in particular firmware updates, is a risk.
If firmware updates fail often the only solution is to replace the part, That could mean a day's downtime.
Can you deal with the negative publicity of having to close your doors due to technical difficulties?
Have you the resources and procedures in place to recover from 15 minutes to 1 hour data loss?
Author: Jason Keane
Your IT Upgrade Starts Here: Contact Us for a Complimentary Assessment
Contact Us